
はじめに
ゼネットシステム事業部の方です。
AWS Glueは、データの抽出・変換・ロード(ETL)をサーバーレスで簡単に実行できるサービスです。
従来のETLツールと異なり、ほとんどコードを書くことなく、S3上のCSVデータを自動で加工・集計できます。
本記事では、AWS Glue Studioのノーコード/ローコードETL機能を使い、
S3上のCSVデータを加工してParquet形式で出力する一連の流れを紹介します。
また、日付列を基に「今月・前月・先々月」を判別する処理も組み込みます。
ETLジョブの概要
今回作成するGlueジョブでは以下を実現します。
-
S3のCSVデータを読み込み
-
型変換と列のマッピング
-
SQLクエリで月判別列を追加
-
列名を日本語に変更
-
加工後データをParquet形式でS3に出力
この構成により、日次処理を完全自動化し、
分析基盤やBIツールにそのまま活用できる形式でデータを蓄積できます。
実装手順(GUIでの操作)
-
Glue Studioで新規ジョブ作成

-
-
Basic propertiesの設定
-
ジョブ名
任意のわかりやすい名前を入力します。 -
IAMロール
ジョブ実行時に使用するIAMロールを選択します。-
S3読み込み・書き込み権限を含むロールが必要です。
-
例:
GlueETLExecutionRole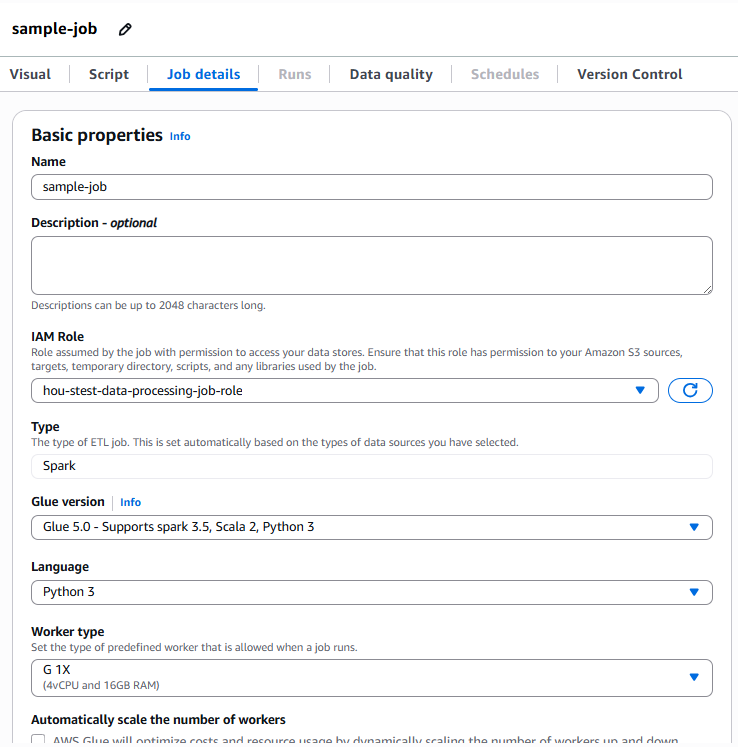
ジョブ名とIAMロール
-
-
ワーカータイプと数
-
小規模データの場合は「G.1X」を選択します。
-
ワーカー数はジョブの規模に応じて設定します。
-
例:
2
-
-
タイムアウト
-
ジョブが自動停止するまでの時間を分単位で指定します。
-
デフォルトは480分ですが、小規模データなら10分程度で十分です。
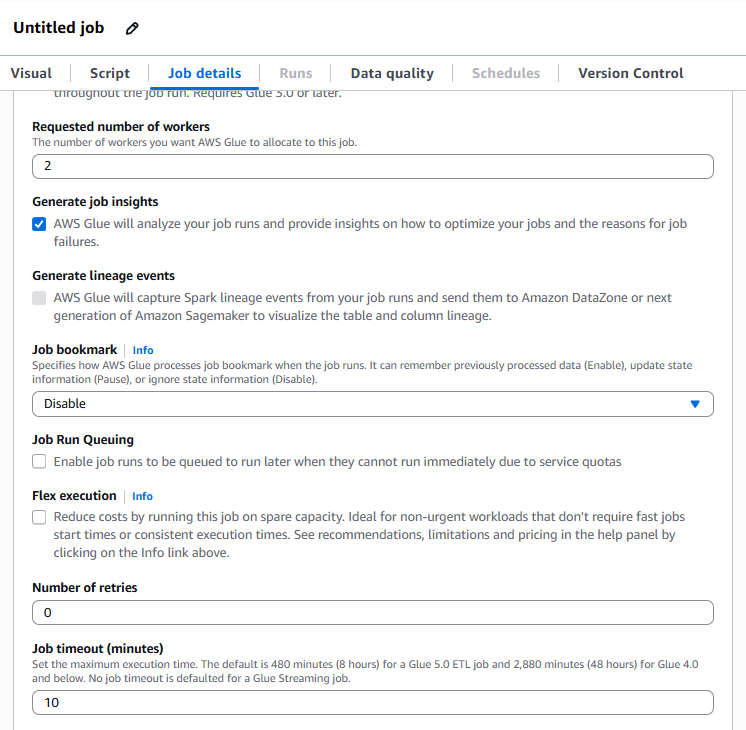
ワーカー数とタイムアウト
-
-
-
-
S3データの読み込みノード追加
-
S3に配置したCSVファイルをソースとして指定します。
-
ファイル形式:CSV
-
ヘッダーあり
-
区切り文字:カンマ(
,) -
パス例:
s3://test-hou/tmp/dataset_10mb.csv
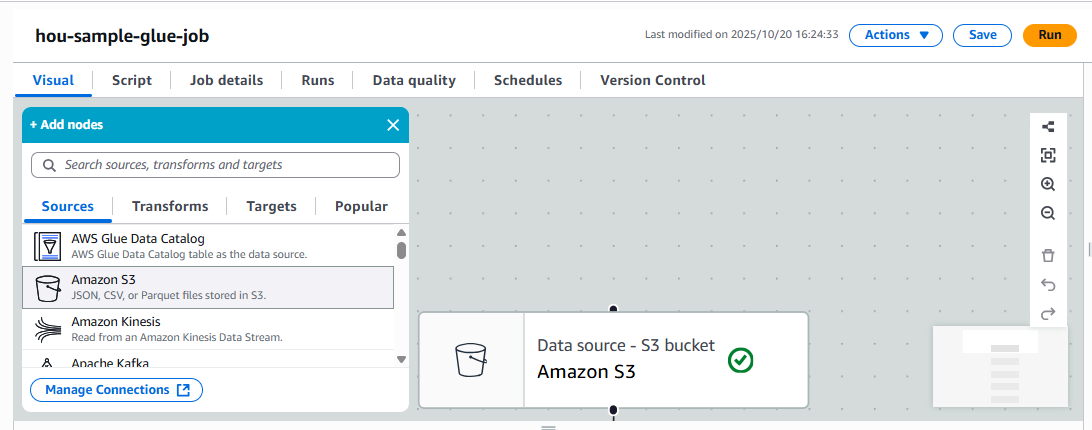
S3データソースノード 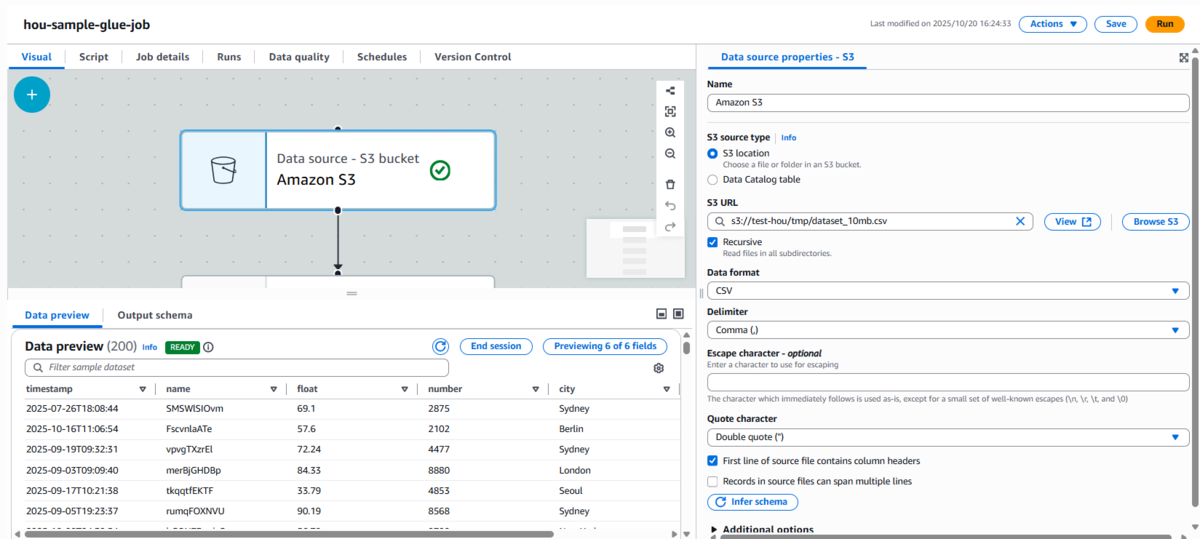
S3データソースノード設定 -
-
-
Change Schema(旧Apply Mapping)で型変換と列マッピング
-
Glue StudioのGUIで、各列の型変換とマッピングを設定します。
-
"timestamp"→timestamp -
"float"→float -
"number"→int -
"sales"→int
この処理により、後続のSQLノードで正確な比較や集計が行えます。
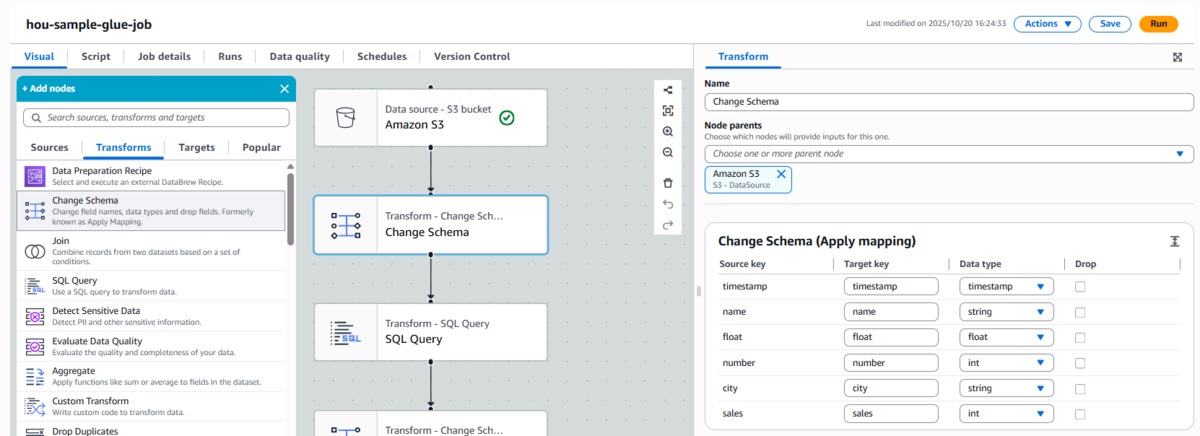
Change Schema ノード設定 -
-
-
SQLノードで月判別列を追加
-
SQLノードを追加し、以下のクエリを設定します。
-
SELECT *, CASE WHEN year(`timestamp`) = year(current_date) AND month(`timestamp`) = month(current_date) THEN '今月' WHEN year(`timestamp`) = year(add_months(current_date, -1)) AND month(`timestamp`) = month(add_months(current_date, -1)) THEN '前月' WHEN year(`timestamp`) = year(add_months(current_date, -2)) AND month(`timestamp`) = month(add_months(current_date, -2)) THEN '先々月' ELSE 'その他' END AS `月判別` FROM sample;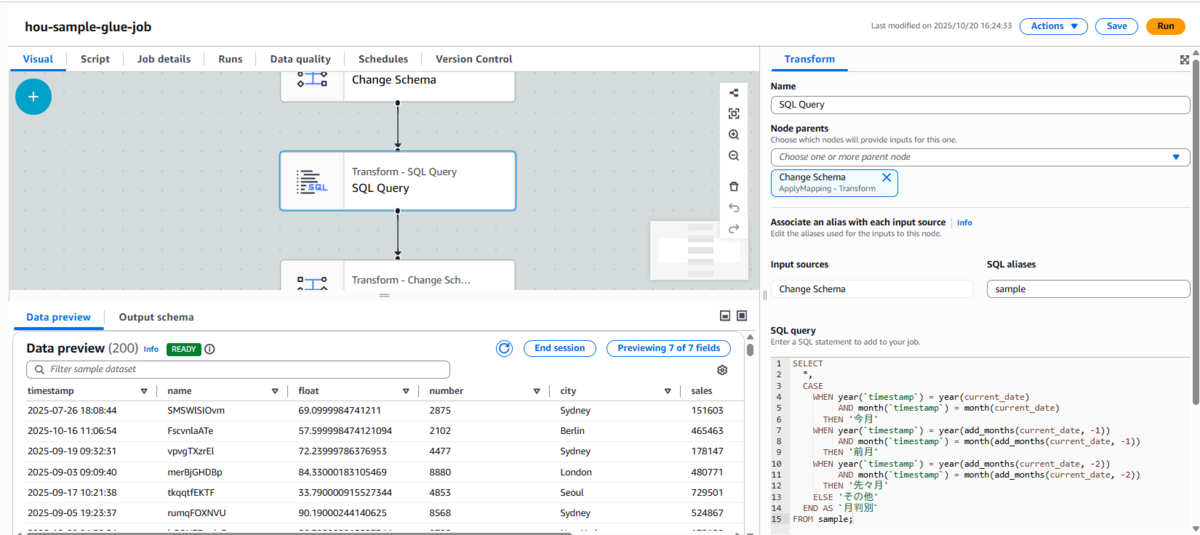
SQL Queryノード設定
-
-
Change Schema(列名変更ノード)
-
列名を日本語に変更して、BIツールで扱いやすくします。
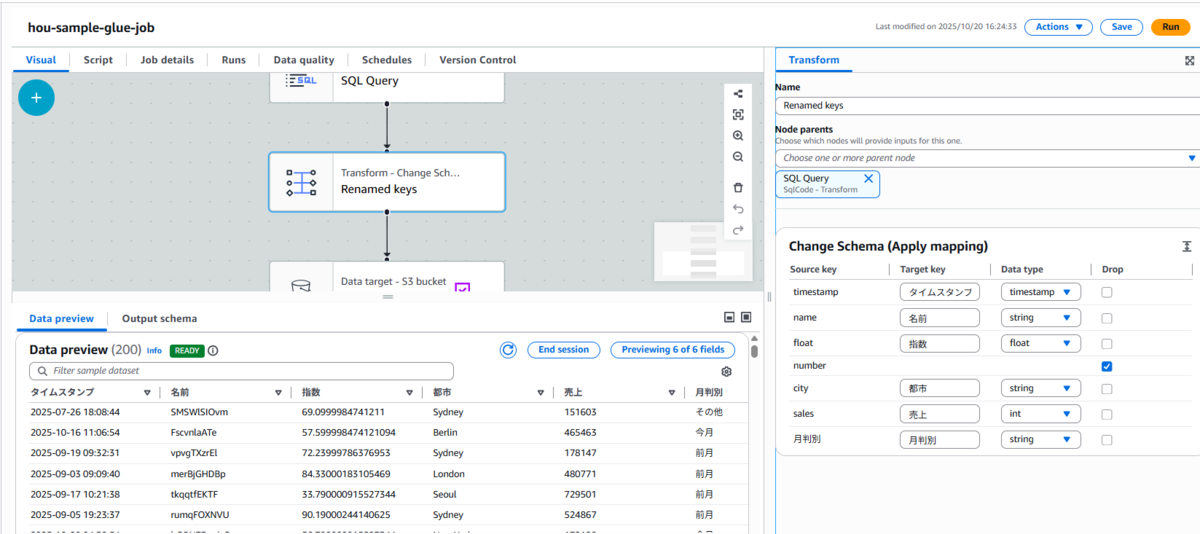
列名変更ノード
-
-
S3出力ノードの設定
-
変換後のデータをS3に出力します。
-
出力形式:Parquet
-
圧縮形式:Snappy
-
出力先パス例:
s3://test-hou/proc/
Parquet形式は列指向で圧縮効率が高く、後続のAthenaやQuickSightでの分析に最適です。
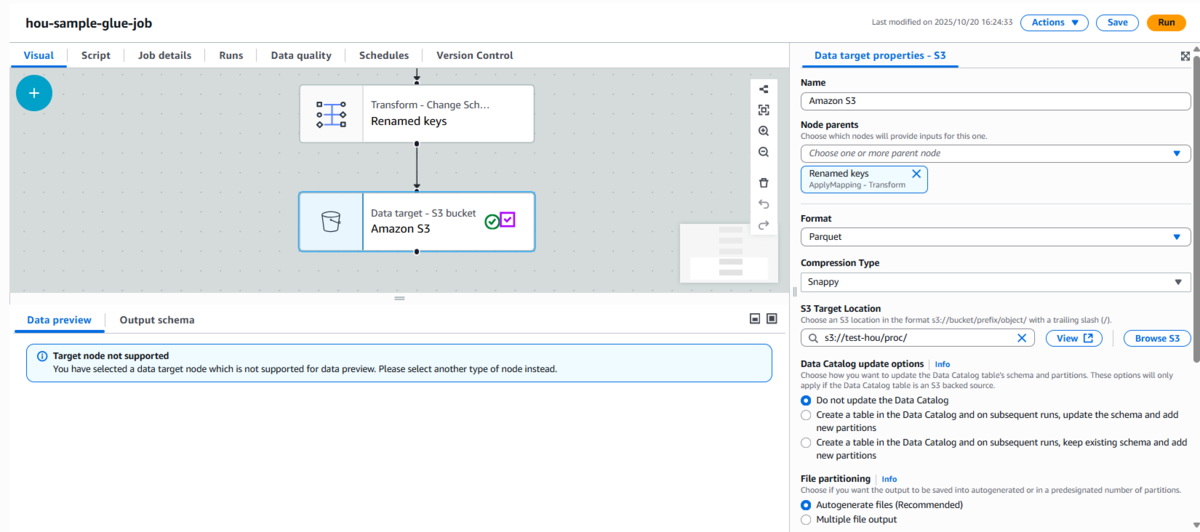
S3出力ノード -
-
実行確認
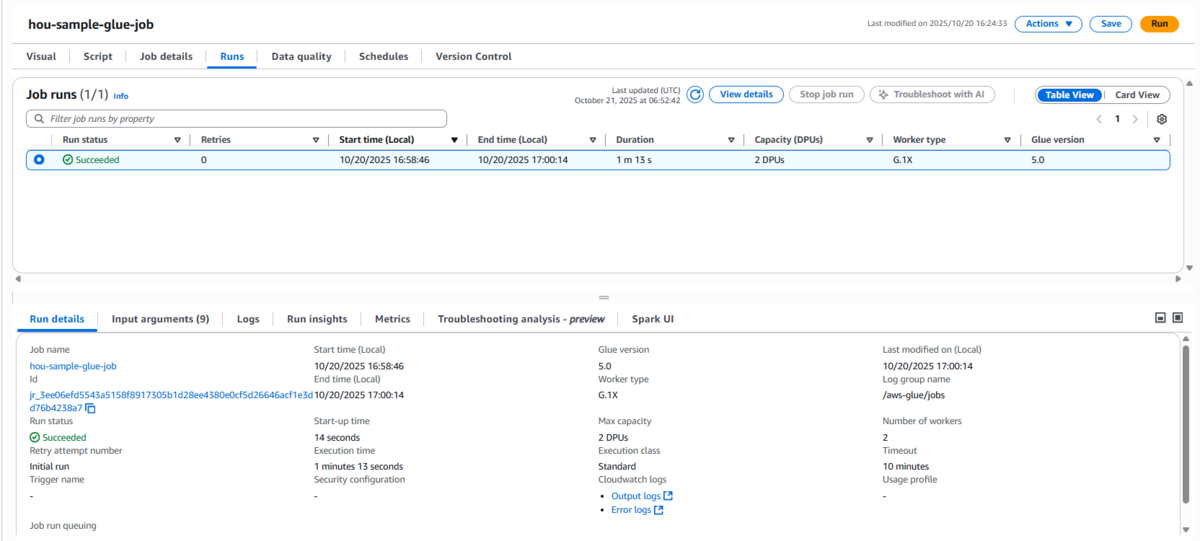
ジョブの設定が完了したら、「Save」 → 「Run」をクリックしてジョブを実行します。
Glue Studioでは、実行結果をコンソール上でリアルタイムに確認できます。
ジョブが正常に完了すると、ステータスが 「Succeeded」(成功) と表示されます。
これでETLジョブが正しく動作したことを確認できます。
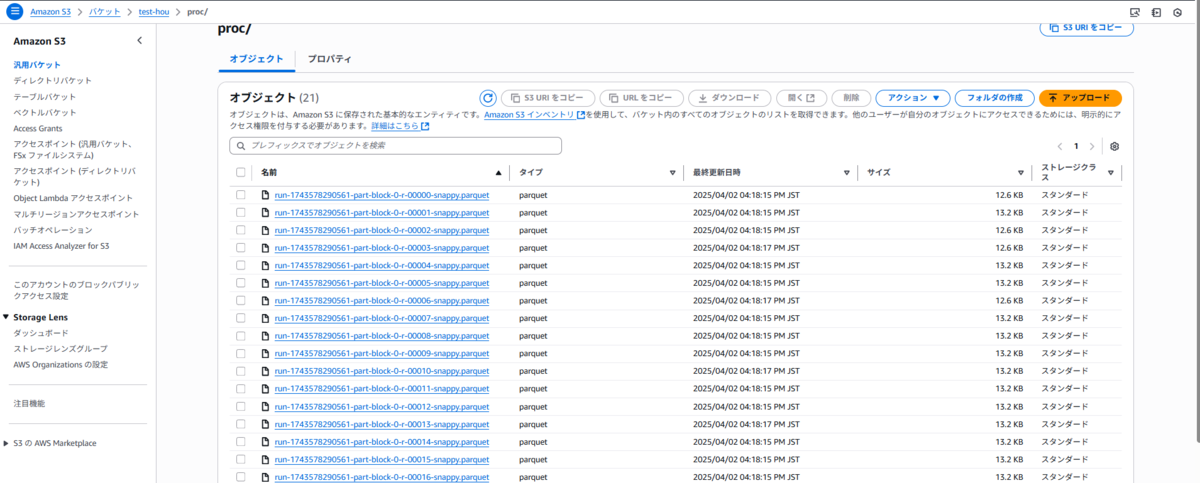
また、蓄積用S3バケット(例:s3://test-hou/proc/)を確認すると、Parquet形式で出力されたデータファイルが保存されていることが確認できます。
これで、GUI操作のみでETL処理が完了しました 🎉
データ品質チェック(Data Quality)
AWS Glue Studioでは、各ノードでスキーマ整合性や欠損値などの簡易的なデータ品質チェックを行うことも可能です。ETL処理の信頼性向上に役立ちます。
まとめ
今回のGlueノーコードETLジョブでは、GUI操作だけで以下の処理を実現しました。
-
S3からCSVデータを読み込み
-
Change Schemaで列の型変換・マッピングを設定
-
SQLノードで「今月・前月・先々月」を判別する列を追加
-
列名を日本語化してBIツールでの利用を容易に
-
Parquet形式でS3へ出力
AWS Glue Studioを活用することで、
コーディング不要・運用コスト最小のETLパイプラインを簡単に構築できます。
今後は、この仕組みを拡張してDynamoDBやRDSなど他のデータソースとも連携可能です。
参照資料